Abstract
Background
Use of intensive longitudinal methods (e.g. ecological momentary assessment, passive sensing) and machine learning (ML) models to predict risk for depression and suicide has increased in recent years. However, these studies often vary considerably in length, ML methods used, and sources of data. The present study examined predictive accuracy for depression and suicidal ideation (SI) as a function of time, comparing different combinations of ML methods and data sources.
Methods
Participants were 2459 first-year training physicians (55.1% female; 52.5% White) who were provided with Fitbit wearable devices and assessed daily for mood. Linear [elastic net regression (ENR)] and non-linear (random forest) ML algorithms were used to predict depression and SI at the first-quarter follow-up assessment, using two sets of variables (daily mood features only, daily mood features + passive-sensing features). To assess accuracy over time, models were estimated iteratively for each of the first 92 days of internship, using data available up to that point in time.
Results
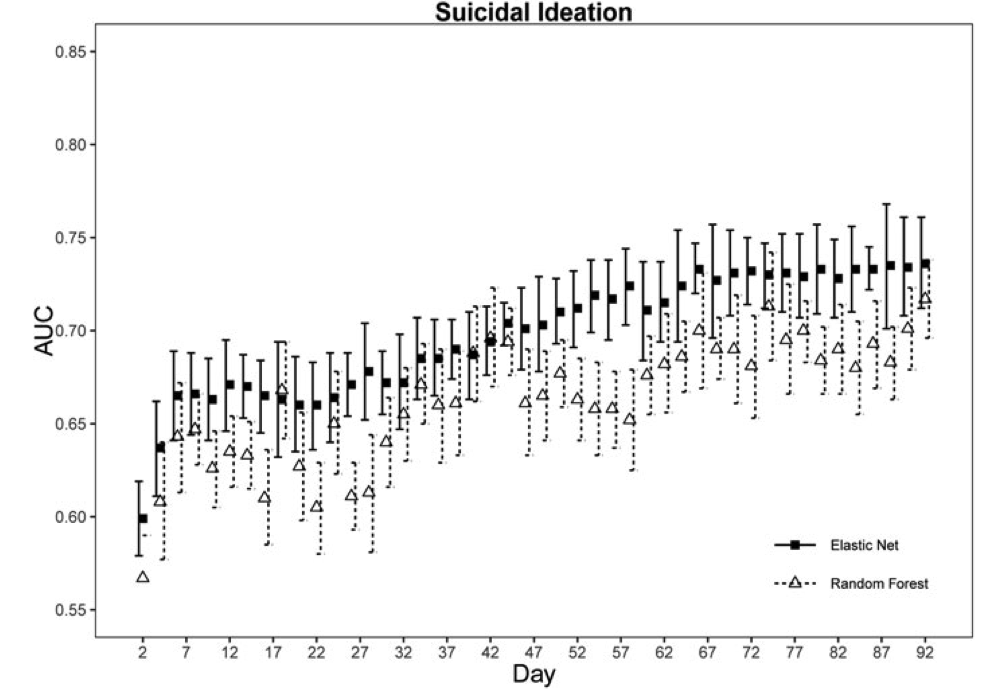
ENRs using only the daily mood features generally had the best accuracy for predicting mental health outcomes, and predictive accuracy within 1 standard error of the full 92 day models was attained by weeks 7–8. Depression at 92 days could be predicted accurately (area under the curve >0.70) after only 14 days of data collection.
Conclusions
Simpler ML methods may outperform more complex methods until passive-sensing features become better specified. For intensive longitudinal studies, there may be limited predictive value in collecting data for more than 2 months.
Keywords Daily diary; depression; intensive longitudinal data; machine learning; medical interns; mood; passive sensing; suicidal ideation