Abstract
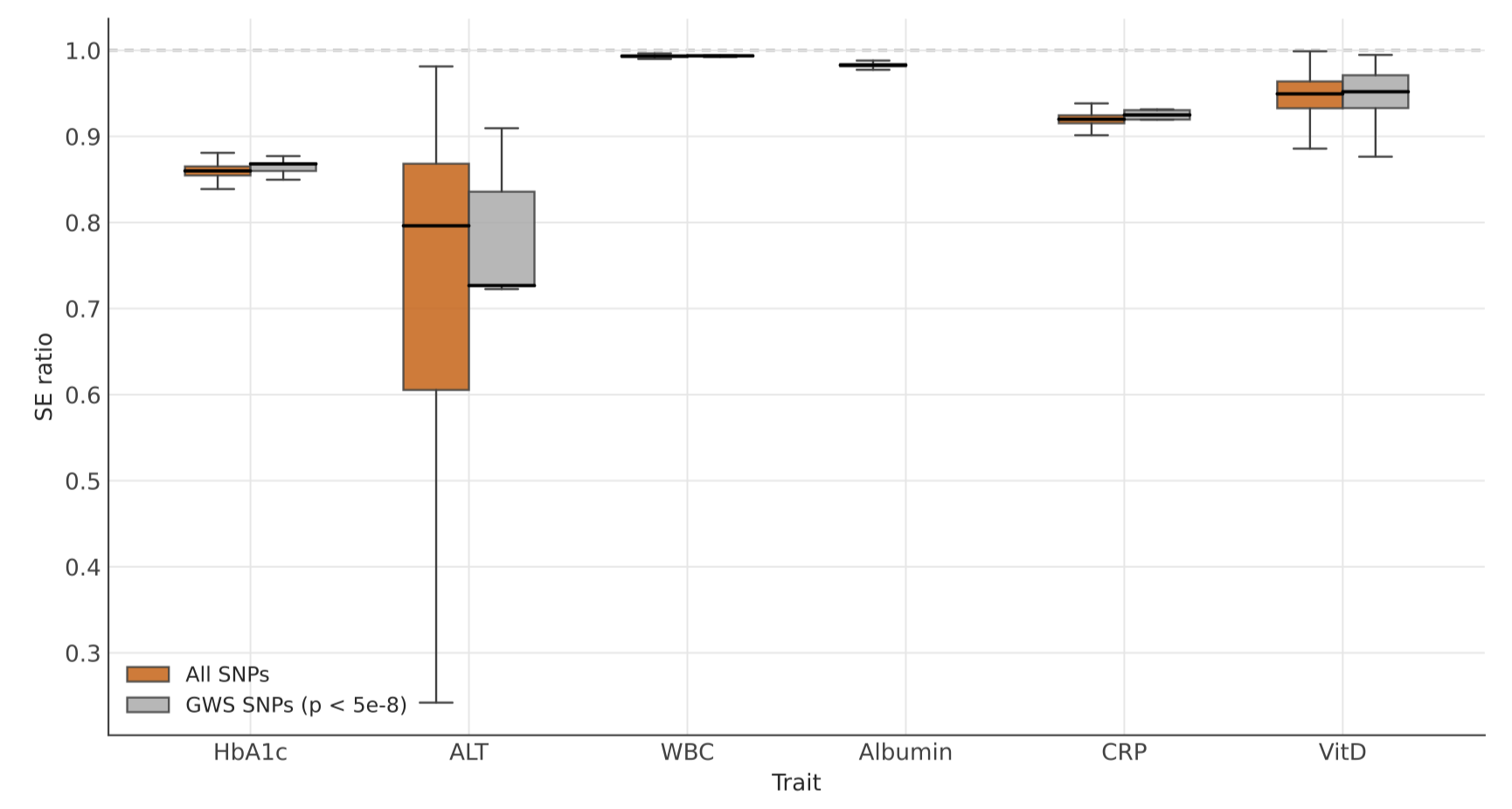
Electronic health record (EHR)-linked biobank data hold tremendous promise for large-scale discoveries via genome-wide association study (GWAS) on diverse phenotypic traits and biomarkers routinely captured in the EHR. However, heterogeneous missingness in biomarkers compromises the validity and efficiency of statistical analyses. Prediction-based (PB) inference methods meet this challenge by using external machine learning (ML) predictions to impute missing biomarker outcomes, thereby improving statistical power and estimation accuracy in association analyses. Yet, their suitability remains unclear when outcomes are subject to clinically informative observation processes, that is, when laboratory tests are ordered based on both measured and unmeasured patient- and health system-level characteristics. In this paper, we review the statistical underpinnings of popular PB methods and then evaluate nine methods, including four PB methods and five traditional missing-data approaches, under an encompassing set of outcome observation processes for continuous and binary outcomes. PB methods can substantially improve statistical power and estimation efficiency when the missing-data mechanism is correctly specified. Under misspecification, however, these gains require both conditional independence between the covariates of interest and the missingness mechanism and independence between imputation error and the missingness mechanism. Using All of Us (AoU) data, we perform GWAS of six laboratory biomarkers and demonstrate that PB methods can replicate known genetic associations while improving efficiency relative to (weighted) complete-case analysis (CCA). Their performance in replicating existing GWAS results in AoU also depends on imputation quality and the underlying missingness mechanism.