Methods paper:

Software:
Abstract
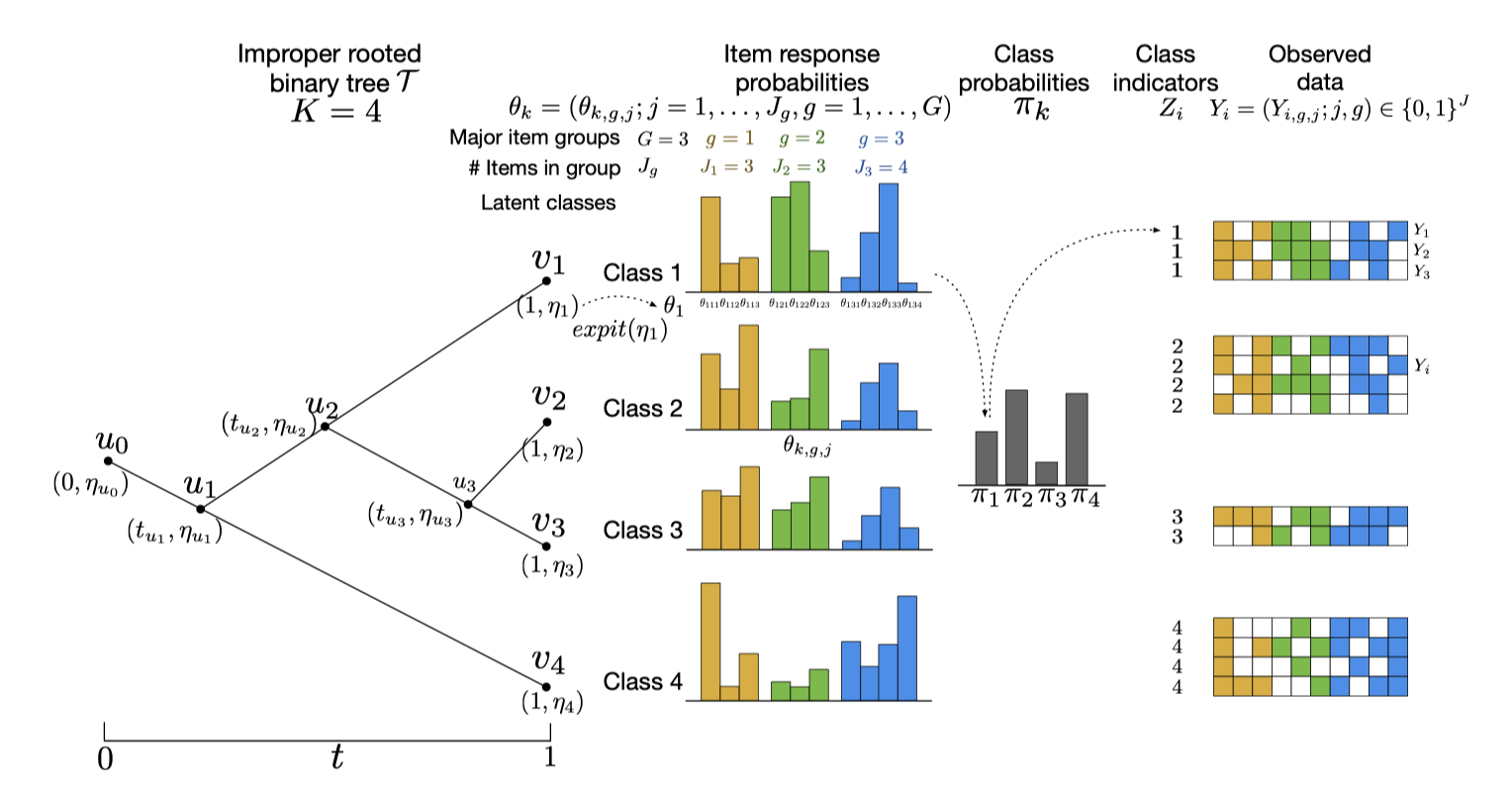
Latent class models (LCMs) is a model-based clustering tool frequently used by social, behavioral, and medical researchers to cluster sampled individuals based on categorical responses. Traditional applications of LCMs often focus on scenarios where a set of unobserved classes are well-defined and easily distinguishable. However, in numerous real-world applications, these classes are weakly separated and difficult to distinguish. For example, nutritional epidemiologists often encounter weak class separation when deriving dietary patterns from dietary intake assessment (Li et al., 2023). Based on the number of diet components queried and the heterogeneity of the study population, LCM-derived dietary patterns can exhibit strong similarities, or weak separation, resulting in numerical and inferential instabilities that challenge scientific interpretation. This issue is exacerbated in small-sized study populations.
To address these issues, we have developed an R package ddtlcm that empowers LCMs to account for weak class separation. This package implements a tree-regularized Bayesian LCM that leverages statistical strength between latent classes to make better estimates using limited data. With a tree-structured prior distribution over class profiles, classes that share proximity to one another in the tree are shrunk towards ancestral classes a priori, with the degree of shrinkage varying across pre-specified item groups defined thematically with clinical significance. The ddtlcm package takes data on multivariate binary responses over items in pre-specified major groups, and generates statistics and visualizations based on the inferred tree structures and LCM parameters. Overall, ddtlcm provides tools specifically designed to enhance the robustness and interpretability of LCMs in the presence of weak class separation, particularly useful for small sample sizes.