Abstract
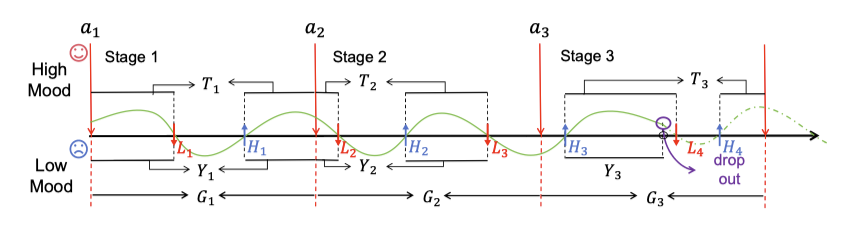
Constructing multistage optimal decisions for alternating recurrent event data is critically important in medical and healthcare research. Current reinforcement learning (RL) methods have only been applied to time-to-event data, and maximize the expectation. However, recurrent event data exhibit a distinct structure and emphasize the probability of event occurrences. In this paper, we incorporate recurrent event data and for the first time propose a RL objective focused on maximizing probabilities. To apply recurrent event data within the RL framework, we formulate a Decision Process optimization framework. During the optimization, we address the challenge of heterogeneous stage counts across individuals by reformulating an auxiliary problem. The proposed optimal policy can be efficiently implemented using Bellman optimality operators. Additionally, we establish the equivalence properties of the optimal policy under the new objective and the unbiasedness of the estimated Q-function. Experiments show that proposed method can converge faster and reduce the variance, and achieve a larger probability compared with the traditional objective.