Abstract
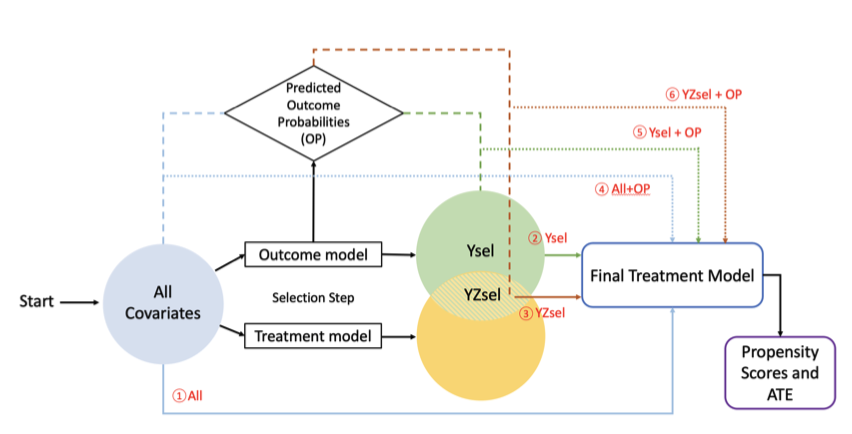
Propensity scores are commonly used to reduce the confounding bias in non- randomized observational studies for estimating the average treatment effect. An important assumption underlying this approach is that all confounders that are associated with both the treatment and the outcome of interest are measured and included in the propensity score model. In the absence of strong prior knowledge about potential confounders, researchers may agnostically want to adjust for a high-dimensional set of pre-treatment variables. As such, variable selection procedure is needed for propensity score estimation. In addition, studies show that including variables related to treatment only in the propensity score model may inflate the variance of the treatment effect estimators, while including variables that are predictive of only the outcome can improve efficiency. In this paper, we propose to incorporate outcome-covariate relationship in the propensity score model by including the predicted binary outcome probability (OP) as a covariate. Our approach can be easily adapted to an ensemble of variable selection methods, including regularization methods and modern machine-learning tools based on classification and regression trees. We evaluate our method to estimate the treatment effects on a binary outcome, which is possibly censored, among multiple treatment groups. Simulation studies indicate that incorporating OP for estimating the propensity scores can improve statistical efficiency and protect against model misspecification. The proposed methods are applied to a cohort of advanced-stage prostate cancer patients identified from a private insurance claims database for comparing the adverse effects of four commonly used drugs for treating castration-resistant prostate cancer.
Keywords causal inference, confounder selection, claims data, high-dimensional, outcome-adaptive, propensity scores, tree-based methods.